Last updated:
The most common CRO mistakes founders make when optimising without specialist help are running tests without a prior research phase, calling tests too early, and optimising the wrong part of the funnel. The result is confident-looking data that does not hold when you look more carefully. If you want a grounding in what CRO actually involves before reading this, our article on what conversion rate optimisation is covers the fundamentals.
A founder reads that someone increased conversion by 30% by changing the colour of a button. They change their button colour. Nothing changes. They conclude CRO does not work for their store. What they actually concluded is that copying a tactic without running the diagnostic is not CRO. It is guessing with extra steps.
CRO is a method, not a list of tactics. The method involves identifying where buyers are dropping off, understanding why, forming a hypothesis, testing it with enough traffic to produce a reliable result, and learning from what the data actually shows. When founders skip any of those steps, the results are unreliable regardless of how well the test appears to be set up. Here are the five mistakes I see most consistently, and what to do instead.
Mistake 1: Running tests before doing the research
Testing without a research phase is the most expensive CRO mistake because it produces clean-looking data about the wrong question. A test tells you whether change A performs better than change B. It does not tell you whether A or B is the right thing to be testing. That requires research.
What research actually means in CRO
Research in CRO means understanding where buyers are dropping off, what they are doing on the pages they visit, and what is preventing them from converting. The tools are behaviour analytics (session recordings and heatmaps), quantitative data (funnel reports, exit rates by page, traffic source analysis), and qualitative data (on-site surveys, customer interviews, support ticket analysis). The output of research is a prioritised list of hypotheses about what is causing conversion loss.
What I see most often is founders who go straight to the test. They pick a page, decide to try a new headline, run an A/B test for two weeks, and call a winner. The test is technically correct. The problem is that the headline was not causing the conversion loss. The research phase would have told them that the buyer was dropping off at the product page because the shipping cost was not visible until checkout.
What to do: Before designing any test, spend at least two hours in your analytics. Look at your funnel report and identify the three steps with the highest drop-off rate. Then use session recordings to watch real buyers on those pages. Look for hesitation, scroll depth, where buyers click, and where they do not. The hypothesis for your first test should come from what you observe, not from what you read worked for someone else's store.
Mistake 2: Calling tests before they are ready
Stopping a test early because it looks like it is winning is the most common statistical error in DIY CRO, and it consistently produces false results. A test that shows 80% probability of being better than the control looks convincing. It is not. At 80% significance, one in five tests that appear to be winning is actually noise.
What statistical significance actually means
The standard significance threshold in CRO is 95%, which means there is a 5% probability that the result is due to chance. Running at 80% means there is a 20% probability. Most DIY CRO tools show you the current significance as the test runs, which creates a constant temptation to call the test when it looks good. The correct practice is to set your minimum detectable effect and required sample size before starting the test and not look at results until you have reached that sample size. Our article on A/B testing for founders covers how to calculate the right sample size for your traffic volume.
Running tests for too short a period
Even if you reach statistical significance, a test run for fewer than two full business cycles can be confounded by day-of-week effects. A test that runs Monday to Sunday will capture a full week. A test that runs Monday to Thursday will show different results from one that runs Thursday to Sunday, because buyer behaviour differs by day. Run tests for at least two full weeks, and ideally two full weeks after reaching your target sample size, not two weeks from launch.
What to do: Before starting a test, calculate the minimum sample size required for your desired significance level (95%) and minimum detectable effect. For a 2% conversion rate and a target of detecting a 10% improvement, you need roughly 20,000 visitors per variant at 95% significance. If you do not have that traffic, you cannot run a valid test at that significance level. Focus on fixing obvious friction instead of running experiments you cannot validate.
Mistake 3: Optimising the wrong page
Fixing the checkout when the biggest drop-off is on the product page is optimising the wrong page. This is extremely common because checkout is where the money is lost most visibly, so it feels like the most important place to work. But if 70% of your buyers are exiting before they even reach the cart, checkout optimisation produces minimal return because the buyers who make it that far are already self-selected for purchase intent. Our article on why your store gets traffic but no sales covers a multi-step diagnostic for finding where the real problem is.
How do you find the right page to work on?
Run your funnel report. Map the journey from landing page to purchase confirmation. Identify the step with the largest percentage drop-off in absolute terms, not relative terms. If 10,000 buyers enter your store and 7,000 exit from the product page before adding to cart, that is where the money is. If 3,000 buyers reach checkout and 2,100 abandon, checkout is the priority. The calculation is simple: drop-off rate multiplied by traffic multiplied by average order value gives you the revenue at stake at each step.
Confirmation bias in page selection: Confirmation bias makes founders optimise the page they already believe is the problem. If a founder built the checkout themselves, they tend to assume it is not the issue. If they received a comment once that the product photos were poor, they focus on imagery. The funnel data is the antidote to confirmation bias. It shows you where buyers are actually leaving, not where you think they are. Trust the data over your intuition about which page needs work.
If you have been running tests that are not producing reliable results, a structured audit is often the fastest way to reset. Request your free audit and we will identify where in your funnel the highest-priority problems actually are.
Mistake 4: Changing too many variables at once
Changing the headline, the hero image, and the CTA button in the same test tells you whether version B outperforms version A. It does not tell you which of the three changes drove the difference. If version B wins, you have no knowledge to apply to the next test or to other pages. You cannot replicate a result you cannot attribute.
The one-variable rule
Test one change at a time. A new headline. A new CTA position. A new trust signal placement. One thing. If it wins, you know the headline was the variable. You can apply that learning to other pages. You can build a hypothesis about why it worked, which informs the next test. Compounding learnings from single-variable tests is how CRO produces durable results over time, not one-off wins.
When does multivariate testing make sense?
Multivariate testing, where multiple variables are changed and tested simultaneously, requires very high traffic volumes to reach significance on each variable combination. For most e-commerce stores with below 100,000 monthly visitors, multivariate testing is statistically impractical. The interaction effects between variables require sample sizes that take months to accumulate at typical traffic levels. Run A/B tests with one variable. Reserve multivariate testing for when you have the traffic to support it.
What to do: For every test you are considering, write down the single change you are making and the single metric you expect it to affect. If you cannot write one sentence describing one change and one expected outcome, the test design is too complex. Simplify until you can. A one-sentence hypothesis is also the clearest way to evaluate what the result actually means once the test ends.

Single-variable tests compound into attributable lifts over time. Multi-variable tests produce wins you cannot replicate and losses you cannot diagnose.
Mistake 5: Treating all visitors as the same
Running one test across all traffic sources, devices, and visitor types produces an average result that may not apply to any specific segment. A change that lifts conversion for mobile buyers might actively harm desktop conversion. A change that works for returning buyers might confuse first-time visitors. Averaging across segments hides the signal.
Which segments matter most in e-commerce CRO?
Device type is the most important segmentation variable for most e-commerce stores because mobile and desktop conversion rates differ significantly, the friction points differ, and the buyer journey differs. A test result that looks flat across all devices may show a strong positive effect on desktop and a negative effect on mobile. Running the test without segmenting obscures both results.
Traffic source is the second most important variable. Buyers from paid social are in a different mental state from buyers arriving from organic search. Paid social buyers are often discovering your brand for the first time. Organic search buyers have often researched and are closer to a decision. A change that helps discovery-stage buyers may not help decision-stage buyers. Our article on good conversion rates by channel includes device-level benchmark data that gives you a baseline for understanding what the right conversion rate looks like for each segment.
How do you segment without overcomplicating the analysis?
Segment your test results by device type as a minimum. If your A/B testing tool allows it, always compare results between mobile and desktop before calling a winner. For traffic source segmentation, a simple split between paid and organic traffic gives you the most useful signal without requiring a complex setup. These two splits take minutes to apply and regularly surface results that an aggregate view would have buried.
The averaging trap: Aggregate results feel authoritative because they represent the full dataset. But an average across two sharply diverging segments is not a representative result, it is a mathematical artefact. A conversion improvement of +4% on desktop and a drop of -4% on mobile averages to zero and looks like a flat test. Both results are real. Neither is visible in the aggregate. Segment before you call anything.
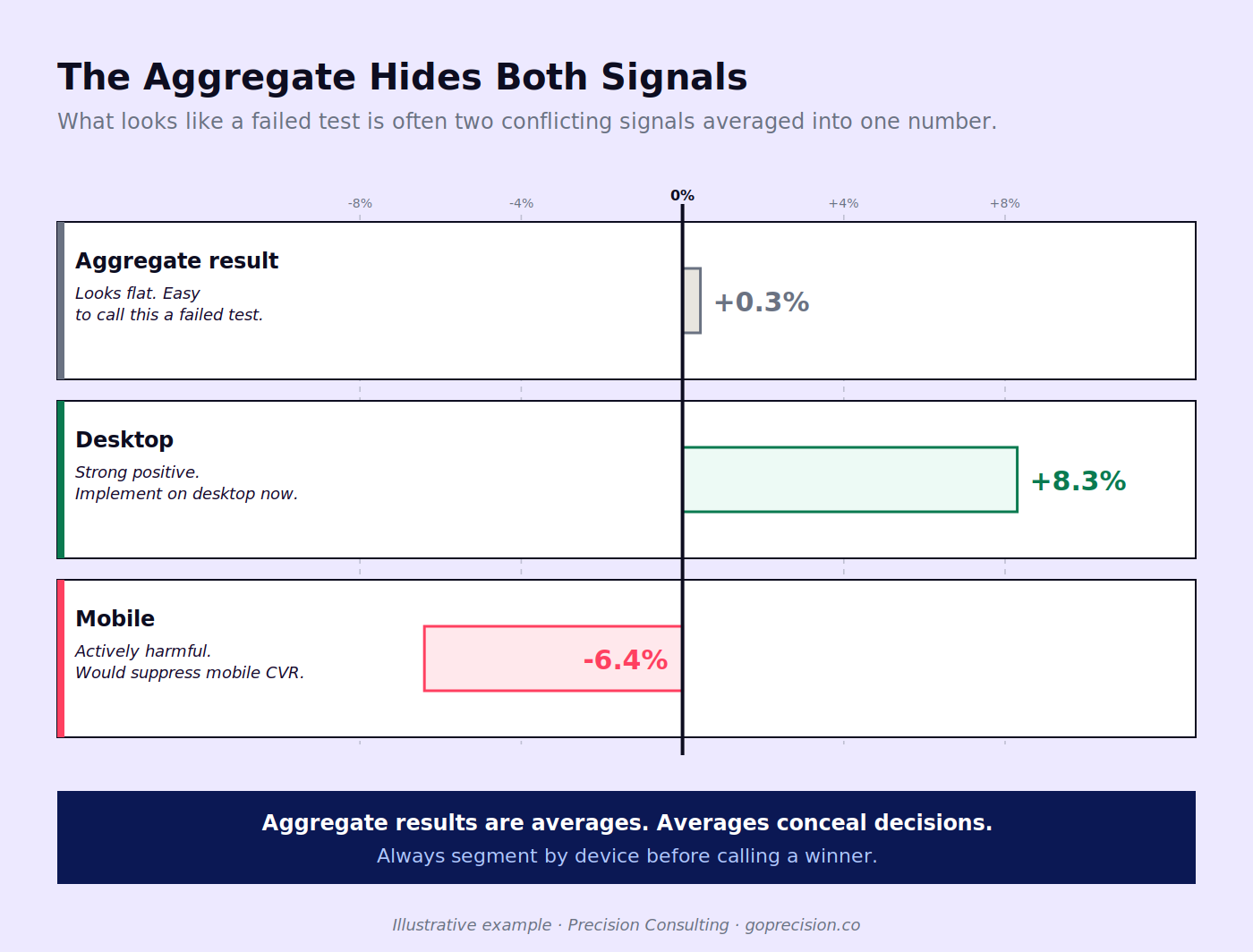
The aggregate result appears flat. Desktop and mobile are moving in opposite directions. Calling the test from the aggregate alone would have missed both signals.
How do you run DIY CRO that actually produces results?
The alternative to the five mistakes above is a simple sequence: research first, then hypothesise, then test one thing at a time, at the right significance threshold, for the right duration, with results segmented by device and traffic source. Run the CRO audit checklist as your research phase. It covers the most common friction points across the funnel and gives you a prioritised list of hypotheses before you design a single test.
The founders who get consistent results from CRO are not the ones who run the most tests. They are the ones who run fewer, better tests with clear hypotheses grounded in data. One valid test that produces an attributable result is worth more than ten tests that produce noise.
- Testing without a research phase is the most expensive CRO mistake. The test tells you whether A outperforms B. The research tells you whether A and B are the right things to test. Always research first.
- Call tests at 95% statistical significance, not 80%. A test showing 80% significance has a one-in-five chance of being noise. Set your required sample size before starting, and do not look at results until you have reached it.
- Find the right page before optimising anything. Funnel reports show you where the largest drop-off occurs in absolute terms. That is the page to work on, not the page you assume is the problem.
- Test one variable at a time. A test that changes three things tells you that the combination works or does not. It cannot tell you which change drove the result, so you cannot replicate it or learn from it.
- Segment results by device type before calling a winner. A change that lifts desktop conversion while suppressing mobile conversion appears flat in aggregate. The average hides both signals.
- Compounding learnings from single-variable tests is how CRO produces durable revenue improvements over time. One valid, attributable result applied across multiple pages produces more value than many underpowered tests that produce noise.
Frequently asked questions
What are the most common CRO mistakes?
The most common CRO mistakes are running tests without a prior research phase, stopping tests before reaching statistical significance, optimising the wrong part of the funnel, changing too many variables in a single test, and treating all traffic as homogeneous. Each mistake produces either no result or an unreliable result that does not hold or replicate.
How do I know which page to optimise first?
Run your funnel report and identify the step with the largest drop-off in absolute visitor numbers. Multiply the drop-off count by your average order value to calculate the revenue at stake at each step. Start with the step that has the most revenue at stake, not the step you assume is the problem.
What statistical significance should I use for CRO tests?
Use 95% statistical significance as your threshold. This means there is a 5% probability the result is due to chance. Running at lower thresholds such as 80% or 90% is common but produces a meaningful rate of false positives. At 80% significance, one in five tests that appear to show a winner is actually noise.
How long should I run a CRO test?
Run tests for at least two full business cycles, typically two weeks, after reaching your target sample size. Do not stop a test early because the results look good. Day-of-week variation means a test run Monday to Thursday will produce different results from one run Thursday to Sunday. Two full weeks capture this variation and give you a more reliable result.
Can I run CRO with low traffic?
Low-traffic stores below 10,000 monthly visitors cannot run statistically valid A/B tests at standard significance thresholds. The sample sizes required take too long to accumulate. Instead, focus on fixing obvious friction points identified through session recordings, heatmaps, and qualitative research. These changes do not require statistical validation because they are corrections to broken states, not tests of preferences.
Predictably Irrational by Dan Ariely: covers confirmation bias and the ways expectations distort how people interpret data, directly relevant to understanding why founders keep optimising the wrong page.
Laws of UX by Jon Yablonski: covers the cognitive principles behind why certain changes affect behaviour, which informs hypothesis quality before you test and helps you prioritise which changes are most likely to move conversion.
If your tests are producing results that do not replicate or hold, the research phase is almost always what is missing. Precision works with founders to build a CRO programme grounded in funnel data, not assumptions. Request your free audit and we will start with where your funnel is actually losing buyers.